LLM Benchmarks (China)
SuperCLUE (The Chinese Language Understanding Evaluation Benchmark CLUE (The Chinese Language Understanding Evaluation)) is a Chinese-developed benchmark originally launched in 2019 and updated since.
Jeff Ding translates
Key Takeaways: There is still a significant gap between GPT-4-Turbo (OpenAI’s best models) and LLMs from China’s top tech giants and start-ups — even for prompts and outputs in Chinese.

Jeff Ding
Full-text copy from his Substack
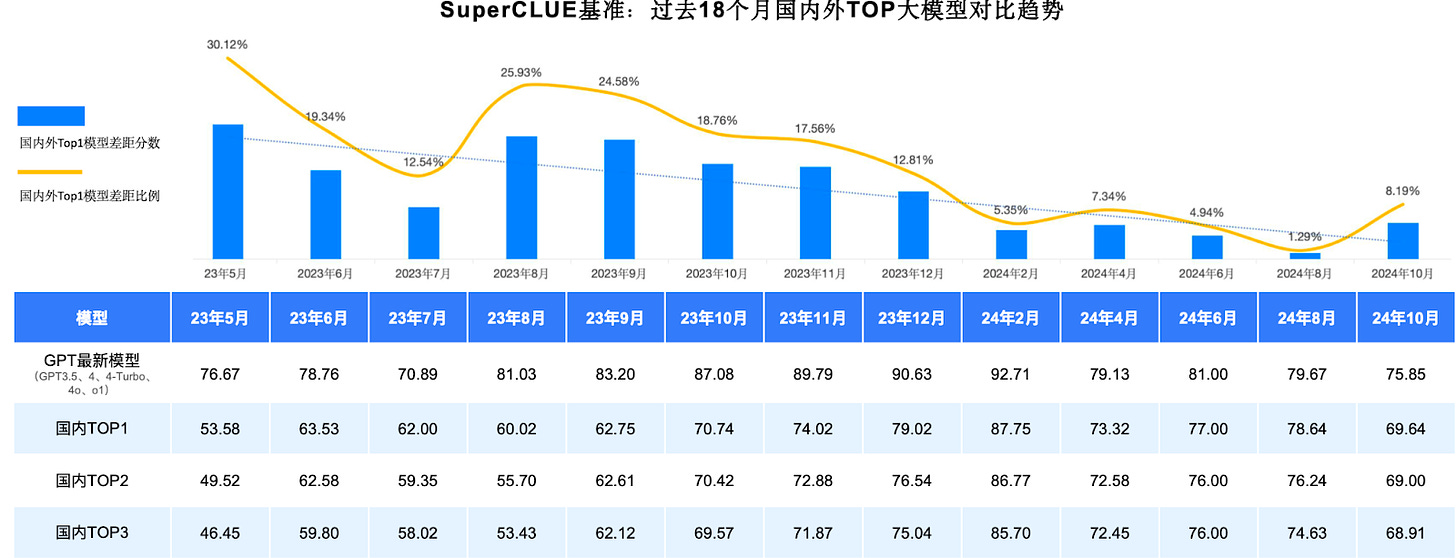
Key Takeaways: Over the past year and a half, the gap in general capabilities between the top Chinese and international models has continued to shrink — from a gap of 30.12% in May 2023 to 1.29% in August of 2024. (Note: this is on Chinese-language tasks)
- However, with the release of OpenAI’s o1, as the last uptick in the image below shows, the gap has once again widened to 8%.
[
](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F38c4535c-90e3-4cb7-a841-2ee714b78f04_1600x613.png)
There is still a large gap when it comes to “Hard tasks” such as high-level reasoning and precise instruction following. The gap between o1-preview’s score on the SuperCLUE-Hard benchmark (64.89 points) and that of the top Chinese model, GLM-4Plus (51.09), is quite substantial.
Here’s an example of a difficult high-level reasoning task (slide 26 of full report): A company plans to host a large conference, with a goal of maximizing the number of attendees while also not surpassing a set budget amount. We know: Venue rental fee = r RMB/square meters; Venue area = A square meters; Food and drink cost for each attendee = c RMB; The total venue rental cost and food/drink cost should not surpass 1,000,000 RMB; The max number of people the venue can accommodate is P; The venue rental fee is related to the number of attendees, with a relationship formalized as r = k p , with k as a constant; How do you set p to enable the most number of attendees? Please use the Lagrange multiplier method to find the solution.
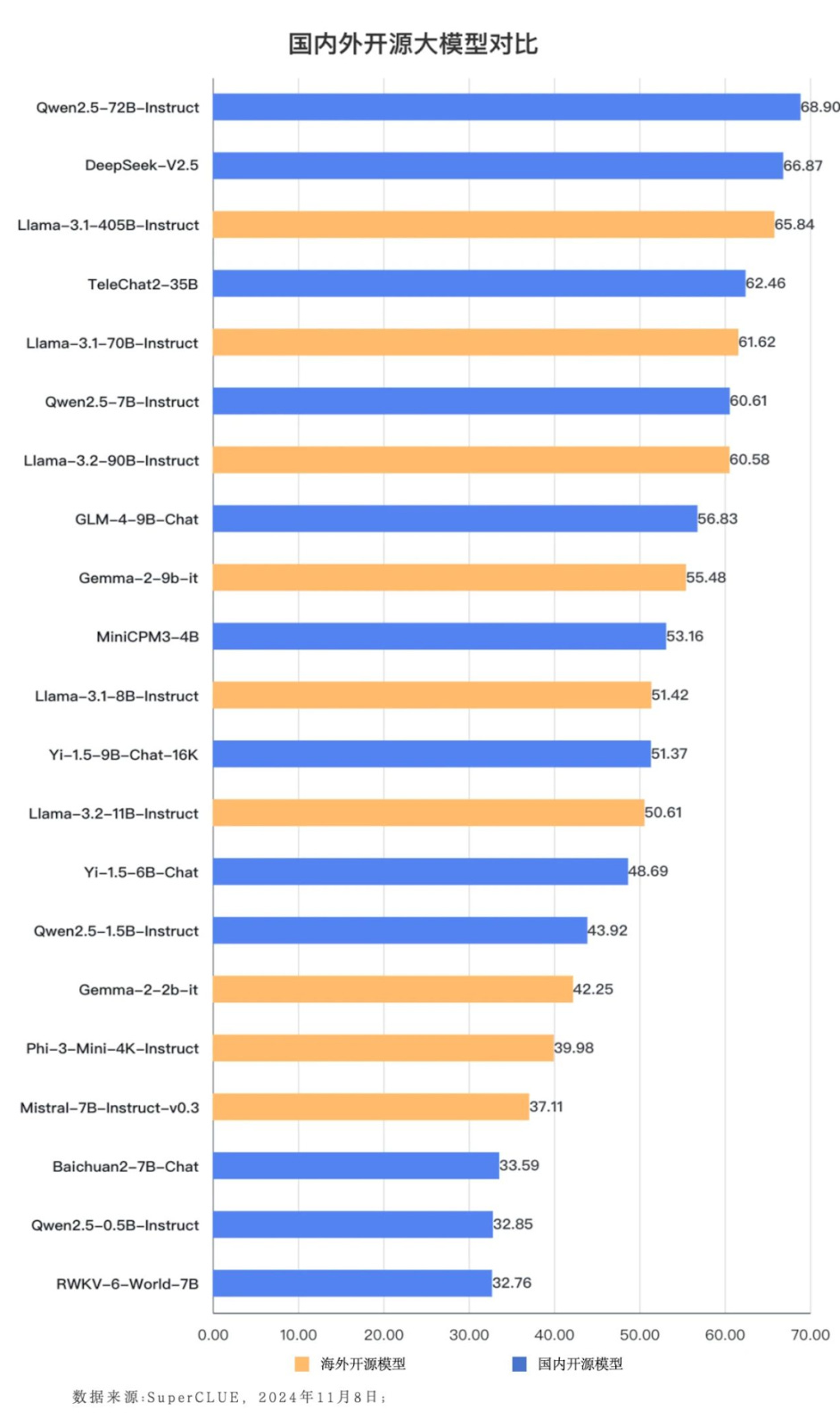
On Chinese-language prompts, Chinese open source models like Qwen2.5 (Alibaba’s model) and DeepSeek-V2.5 outperform their international competitors, including Llama’s best models.
[
](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fa72ea838-9899-4143-b7a6-d962f9a55e16_942x1600.png)
Screenshot above shows Chinese open source LLMs (in blue) compared to international open source models (in yellow). In fact, Chinese open source models are nearing the performance of the world’s top closed-source models on SuperCLUE: “Qwen2.5-72B-Instruct scored 68.90 points, which is 2.34 points lower than the average of the top 5 closed source models in the world”
This aligns with the trend of small-sized models exhibiting strong progress, possibly providing the best “bang-for-buck”, or balance between performance and power consumption for developers. In SuperCLUE’s ranking of models under 10B parameters (slide 38 of full report), for instance, both Qwen2.5-7B-Instruct and GLM-4-9B-chat ranked higher than Google’s Gemma-2-9b-it model.
FULL-ish Translation including some other notes I took on interesting slides from: Chinese Large Model Benchmark Evaluation October 2024 Report